Serving Hybrid Models at Scale in llm-d






For most of the transformer era, the KV cache rested on a quiet assumption: one model, one uniform cache. Every layer attended the same way, every block was the same size, and everything built on top of the cache (allocators, offload connectors, schedulers) could treat it as a single pool.
Hybrid models broke this assumption. Most of today's new cutting-edge models opt for mixing attention types within a single model (full attention next to sliding-window, linear, or Mamba layers), making the cache heterogeneous: different layers now hold different amounts of state, in different shapes, with different reuse rules. A cache block that used to be allocated as one uniform unit is now constituted of several distinct parts.
To serve a hybrid model efficiently, an AI inference platform has to handle that heterogeneity in at least three aspects of the stack:
- GPU Memory Allocation: How the cache is laid out and allocated on the GPU. vLLM solved this with its Hybrid Memory Allocator (HMA), rebuilt around a unified allocator (see Hybrid Models as First-Class Citizens in vLLM).
- KV Offloading: Extending the KV cache to CPU and storage. Without HMA awareness, an offloading connector turns the HMA off and therefore discards the GPU memory improvements or potential data movement savings.
- KV-Aware Routing: Sending each request to the right model-server replica. Ignoring hybrid memory structure may erroneously list nodes as having or not having the required KV data based on information stemming from just part of the layers.
This post describes how we extended the vLLM solution for GPU memory handling also to KV offloading and routing. By doing so, llm-d's tiered KV cache management significantly improves throughput and latency at high rates.
KV Cache Offloading for Hybrid Models
The KV cache grows linearly with sequence length, and the workloads people actually run now (agentic loops, multi-turn conversations, long reasoning traces) push context lengths into the thousands of tokens. At those sizes, the KV cache is one of the largest consumers of GPU memory. KV offloading extends this cache by using CPU DRAM and even storage, to keep more KV data available for reuse across requests. Our KV offloading path builds on the vLLM native offloading connector and llm-d storage offloading.
Handling KV Data for Hybrid Models
Hybrid models interleave different attention types across layers, and each type stores state differently. Take for example gpt-oss-120b which we use throughout this blog as a concrete example (though the connector handles any hybrid model): This model interleaves between Full Attention layers (FA) and Sliding Window layers (SWA). Its full-attention layers cache every token, so a 100K-token request holds all 100K tokens of KV in these layers, while its sliding-window layers keep only the last 128 tokens, no matter how long the request runs. Two layer types in one model, with cache footprints that can differ by orders of magnitude.
Frontier models keep diverging from uniform full attention models. Mamba and linear-attention layers (Jamba, Qwen3.5) hold a single fixed-size state instead of per-token KV. In such models, rather than keeping a KV stream, checkpoints of intermediate states are maintained and offloaded. New models like Google's Gemma 4 interleave two types of attention, local sliding-window and full global. DeepSeek V4 goes furthest, mixing compressed attention at two ratios with a short sliding window inside a single model built for million-token context, a five-way cache stack that vLLM folds into a handful of shared page-size buckets just to serve it.
With the Hybrid Memory Allocator (HMA) enabled, vLLM splits the cache into groups – each group has a uniform attention type and is managed separately. KV data for "old tokens" in a sliding-window group may be evicted, whereas in a full-sequence group these have to be maintained for the entire prompt. For gpt-oss-120b HMA creates two groups: full-attention and sliding-window, shown in Figure 1. With the HMA disabled, these groups collapse into a single full-attention buffer requiring keeping the full attention in memory for all layers. While the model still saves on compute (since SWA layers only compute on a fixed-size window), the memory saving is thrown away.
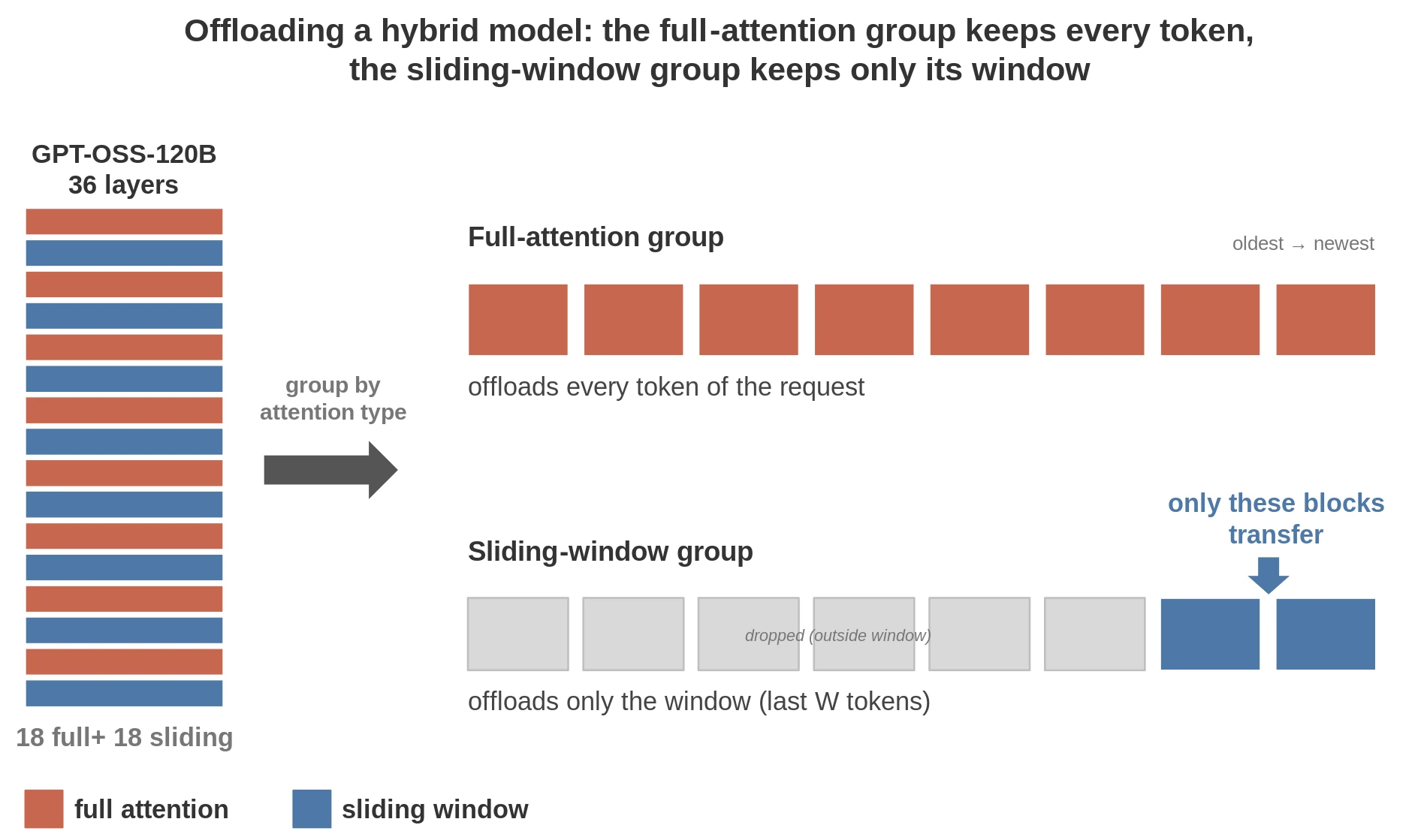
Figure 1. Per-group offloading: full-attention keeps every block, sliding-window keeps only its window.
Handling Hybrid KV by an Offloading Connector
Prior to our changes, an offloading connector built for the uniform world handles a hybrid cache in one of two bad ways: Either forgo offloading altogether or forgo the use of HMA. The second is not a failure but a silent slowdown: vLLM falls back to managing offloading uniform attention blocks and offloading requests succeed, but the GPU memory savings are lost, and every KV load ends up moving more data than it should.
Making the connector genuinely HMA-aware came down to the following changes:
- Per-group tensor subsets. vLLM makes the connector aware of which tensors belong to which group and their layer type. Lookups of blocks in the connector are also group aware.
- Per-group offloads. Rather than offloading a single KV block for a chunk of tokens, each group of layers offloads its separate KV data. In storage, this amounts to a separate file per group. For example, in gpt-oss this means two files per chunk instead of one, which the I/O pool can move in parallel.
- Partial transfers. Some groups only require partial loading of KV data. Sliding-window layers need only the KV of the last tokens in a prompt, so the connector transfers only the in-window blocks. In the case of storage, this often starts from an offset partway into a file rather than the beginning of the file.
We built these changes into the vLLM native offloading connector and llm-d FS connector, handling both the CPU and storage tiers. This allows vLLM to use HMA along with the connector and, as shown below, leads to significant performance improvements.
Performance Benefits: Nearly Double the Load Speed
When a request prefix already lives in the offload tier, how fast can we pull it back? We ran a small microbenchmark: run ten distinct 128k-token prompts concurrently. On an initial "cold" pass their KV is written to the offload tier. Then we repeat this on a "hot" pass (with GPU cache disabled) in which the KV data is read back from the offload tier. We measure how long the hot batch takes to complete its KV loads and decode one token for all ten requests (similar to TTFT, but for the whole batch).
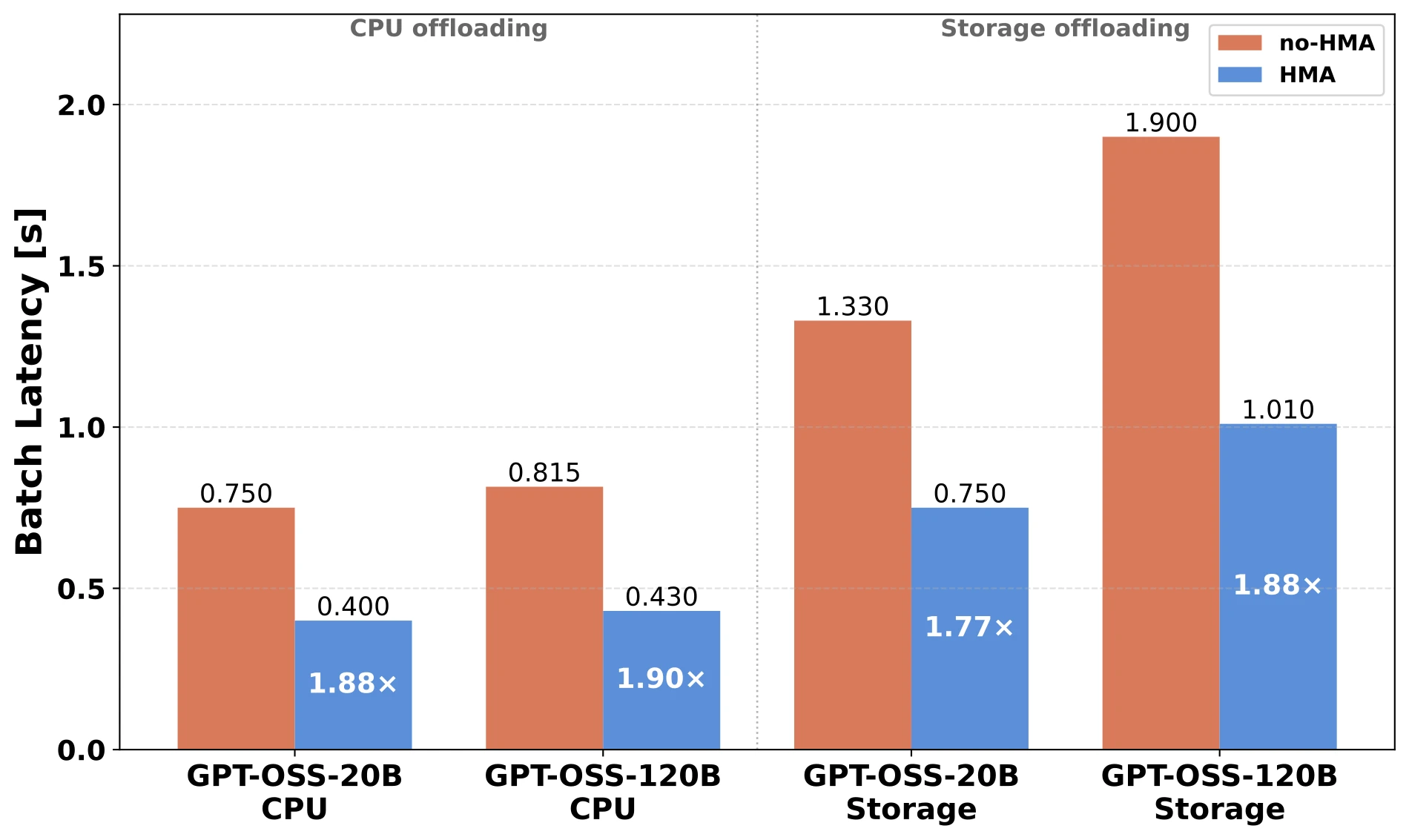
Figure 2. Batch KV load latency across CPU and storage tiers with HMA and without it. Models are gpt-oss-20b (TP=2) and gpt-oss-120b (TP=4) on NVIDIA H100 GPUs. Block size is 16 tokens for the CPU tier and 256 tokens for the storage tier.
The results (in Figure 2) show that HMA-aware reads are 1.8x to 1.9x faster on both tiers and both model sizes. The source of these benefits is in the sliding window layers that only need to load the last 128 tokens worth of KV cache instead of the full attention for the entire 128K tokens. On the offload side (after initial prefill) we did not see this benefit as we still chose to offload all the KV data. This direction is done asynchronously and thus is less critical.
Scaling Benefits of HMA-Aware Offloading
HMA pays off irrespective of offloading, because sizing each group to its real need frees a lot of HBM. For example, for a gpt-oss-120b model, vLLM predicts an increase of 1.77x more KV cache capacity when turning the HMA configuration flag on (as seen in vLLM's log messages). This is again due to the lower capacity that the sliding window layers take. When testing this with offload tiers underneath, this effect compounds: the GPU can cater to more requests, and similarly, the CPU tier can serve more requests by evicting more non-critical KV data from the sliding-window layers.
To show the scalability of using offloading, we follow the scalability test from our previous post, Native KV Cache Offloading to Any Filesystem with llm-d. This test sweeps a growing number of users each sending its own (previously seen) prompt of 16K-token with single-token decode. The test runs at maximum query-per-second rate of 80 and max-concurrency of 80 and measures throughput in tokens per second. As the number of users grows, each configuration eventually saturates its memory capacity and drops to prefill level throughput.
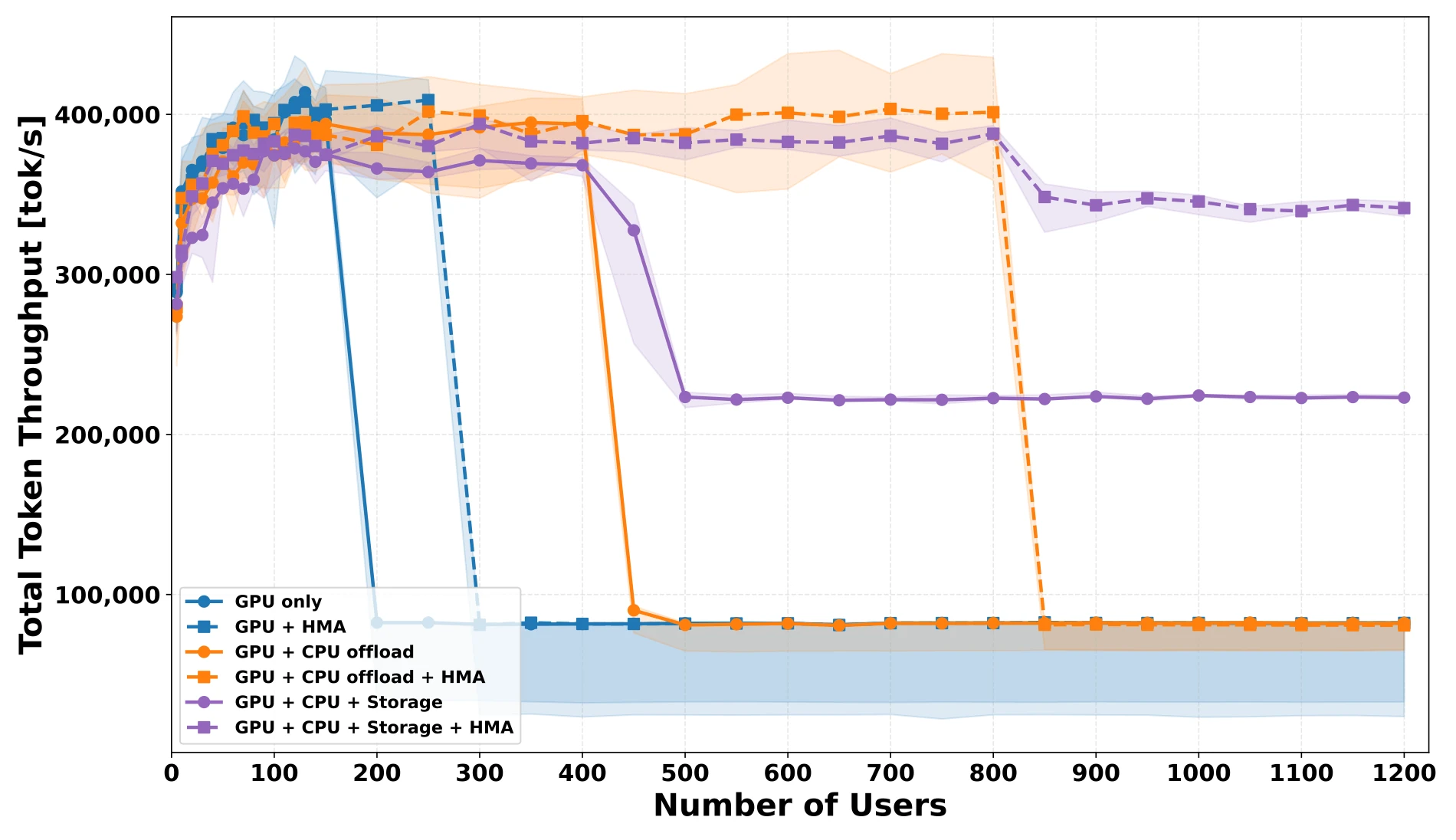
Figure 3. User scalability test across tiers with gpt-oss-120b (TP=4) on NVIDIA H100 GPUs, with HMA and without it.
HMA-awareness produces two positive effects in this experiment, shown in Figure 3. First, it shifts each saturation cliff to the right: the GPU holds more users with HMA before it saturates, and the CPU tier does the same once it takes over. The storage capacity is large enough, so we never hit this cliff. Second, it raises the sustained throughput of the slower tiers: with storage added, the GPU + CPU + storage stack settles onto a much higher plateau than without HMA, and manages to sustain this high throughput to the largest user counts tested.
KV-Aware Request Routing
Everything so far ran on a single vLLM instance: the read speedup, the capacity, the throughput under load. Scaling past one instance is where it gets harder, especially without shared storage, because a bigger effective cache per GPU and CPU only helps if each request lands on the replica that already holds its prefix. Spread requests blindly across a fleet and the cache hits drop sharply. Routing requests to where their cache lives is what llm-d does, and it was the subject of our earlier post, KV-Cache Wins You Can See, where prefix-aware scheduling gave the scheduler a global view of the cluster's caches. We extended that idea across tiers, so the scheduler scores not just each replica's GPU cache, but its CPU offload tier too, and routes accordingly - we call this multi-tier KV management.
Routing rides on the KV-events vLLM emits to externalize its cache state. We extended those events to cover the CPU tier, and to carry HMA-group information for hybrid models - so the router can see that a prefix's full-attention layers are still resident even after its sliding-window layers have rolled out of the window, rather than treating the whole block as gone. For models that pair full attention with sliding-window layers, like gpt-oss, the scorer already uses this to route on the layers that are actually retained. Models that are purely sliding-window, or that mix several window sizes, are the harder case, and a dedicated scorer to handle them optimally is in progress; the results below come from the existing tier-aware scorer.
To exemplify routing with hybrid models we benchmarked a fleet of 16 gpt-oss-120b servers at three levels of management, sweeping 5 to 40 QPS (workload: 250 prefix groups, 5 prompts per group, 16K-token system prompt, 256-token question, 256-token output):
- GPU-only KV management: the scheduler scores only the GPU cache (our baseline).
- GPU KV management + CPU offloading: a CPU tier absorbs the overflow, but routing still scores only the GPU.
- GPU+CPU KV management: the scheduler scores both the GPU and the CPU tier, so each request routes to wherever its prefix actually lives.
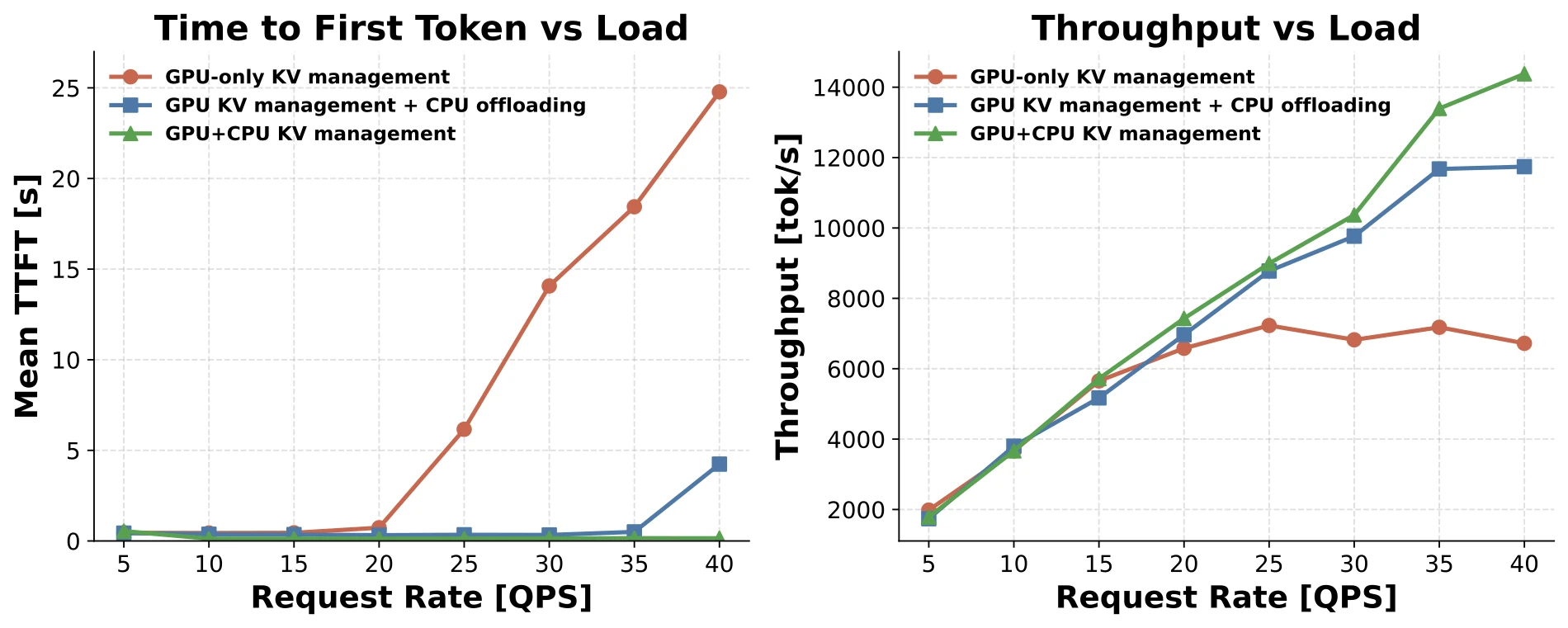
Figure 4. KV cache management across a 16-server gpt-oss-120b fleet (TP=1, one NVIDIA H100 per server): TTFT and throughput vs request rate.
The payoff shows up under load. Past about 20 QPS the GPU-only baseline saturates and its TTFT climbs into the tens of seconds as requests queue. Adding a CPU offload tier helps: at 40 QPS it lifts throughput about 75% over the baseline while holding TTFT low. But the real win comes from managing both tiers together. With GPU+CPU KV management, throughput rises roughly 115% over the baseline at 40 QPS, and TTFT stays essentially flat across the whole sweep.
That gap is llm-d's value: the offload tier only reaches its full potential when the scheduler knows what it holds and routes to it. Capacity is a property of an instance; throughput is a property of placement.
The full setup, the per-QPS results, and step-by-step instructions to run it yourself are in the llm-d tiered prefix cache guide.
What's Next
The experiments in this post used the standalone llm-d FS connector. Yet the same HMA-aware offloading was also fully implemented in the new multi-tier connector that has been upstreamed into vLLM and will replace the standalone connector going forward. See the vLLM KV offloading guide. The multi-tier design is more than just packaging. With CPU and storage managed as tiers of one connector, CPU serves as a hub for hot data and a staging area for slower storage.
The HMA results here rely on canonical KV-cache allocation for HMA models in vLLM (PR #37885), so reproducing them needs a vLLM build that includes it.
HMA itself is not a solved problem. Every new model brings new attention layers, and each one is another cache group the connector has to handle correctly. As context lengths and model counts keep growing, getting that offloading right is no longer a nice-to-have; it is what keeps serving affordable.
Get Involved with llm-d
- Explore the llm-d Community Quickstart Guide → Start here
- Join our Slack → Get your invite and connect with maintainers and contributors
- Explore the code → Browse our GitHub organization
- Attend meetings → All meetings are open! Add our public calendar